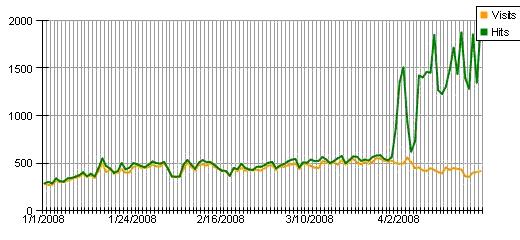
The answer is, they are very accurate counts of requests made to the website server, which doesn't mean much of anything. Take the graph for my self publishing blog feed shown above. The "hits" number shot up last month when I wrote a popular post about potential changes at Amazon, may have led some subscribers to keep checking their readers to see if there was more news. Or possibly, I picked up a handful of new subscribers who check their newsreader several times an hour. But most likely it's a badly written piece of distributed software that keeps checking the feed every couple minutes. For what it's worth, Google's Webmaster Tools reports that the number of subscribers to my blog they're aware of is 67, and considering I've never attempted to build a subscriber base, I wouldn't be a bit surprised if that's accurate. The rest of the 400 or so daily "visits" to my feed are probably from legitimate multiple checks or other noise of one sort or another.
The second example I'm giving is from a static publishing page on my website, one that's hardly changed since it was first posted five or six years ago. About two years back, it showed a sudden jump in traffic that left me scratching my head. The data in my server logs reported that this surge was from "direct" visitors, always a highly suspect category for a publishing website. If you're running a news site or a bank, you can expect a lot of direct traffic from from people who type in the site name or who have you on their favorites, but when most of traffic to a static book excerpt shows as "direct", something is fishy.
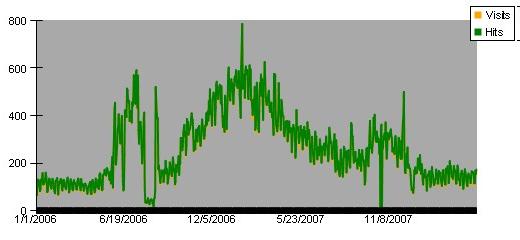
Sure enough, when I added a a script based counter to the page, it ignored all of the direct traffic and showed that the 80% of the visitors to the page continued to come from search. This fake traffic persisted for over a year and a half and could come back at any time! Was it due to a crude attack on my site, a bot net, an angry reader with nothing better to do with their time? I have no idea and don't really care. The important thing when you're publishing for a living is to be able to recognize unnatural patterns in the statistics so that you don't get tricked into wasting your resources on publishing books for a ghostly audience. The best rule-of-thumb I can offer is to ignore visitors that aren't coming from a referring link or a search engine.
No comments:
Post a Comment