If I ran the copyright office and we fell a month behind on processing copyright registrations, I’d be working sixteen hours a day and nursing an ulcer. If we fell two months behind, I’d be handing out pink slips to my Federal employees, long spoiled with 99% positive job approval ratings, and to hell with their unions. If we fell three months behind processing registrations, I’d be so deeply ashamed that I would commit Seppuku.
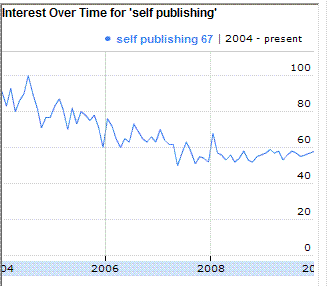
I realized a couple weeks ago that a copyright registration I submitted back in the summer of 2008 still hadn’t been processed, so I went to their website to look for an e-mail address to complain. What I found was a note stating that an electronic registration may take up to six months for processing and the paper form registration may take up to eighteen months to process. In other words, as far as the Copyright Office is concerned, my registration certificate wasn’t even overdue yet! When I decided to write a post today with a copyright process flowchart I had kicking around, I went back to the copyright website to get a screen shot of the current copyright processing times:
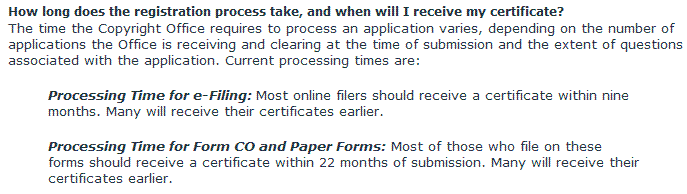
That’s right, they’ve fixed the problem by changing their expectations. The copyright office now considers it normal to take up to nine months to process electronic registrations, and up to twenty-two months to process paper registrations. By that standard, they may feel I have nothing to complain about until April or May 2010. Shame on them! Shame on the Library of Congress, on the Copyright Office, and shame on every manager and employee who is waiting out their time for a pension and moaning about their workload and budgets. If the fault lies in their own incompetence, they should be fired, and if the fault is truly beyond their control, they should resign en masse in protest.
Yes, I’m speaking to you directly, employees of the copyright office. Have you no shame? Have none of you ever worked in real jobs, such that you know the difference between accomplishing a task and punching a clock? Do any of you really believe that the blame for your inability to perform a simple job lies with the Congress, or with the American people? Whatever money you are paid, you are stealing from the fee-paying publishers and taxpayers. The copyright office is a scandal and you should all be fired with prejudice.
I have two suggestions for addressing the problem. First, the process of registering copyrights should be split off from the depository function of the Library of Congress for all publishers, authors, creative artists, etc, who are willing to submit an electronic copy of the work separately. As those of us who have filed electronic copyright registrations using the ECO (Electronic Copyright Office) website know, the process is a bad joke terminating in printing a form to be mailed in. There is no reason in heaven or on earth for copyright registration not to have a purely electronic option, where registration receipt is instantaneous with submission. The so-called review process the copyright clerks occasionally delve into is a pointless exercise at best. The copyright clerks cannot hope to do the research for every (or any) copyright that would determine whether material is truly 100% original and properly credited and whether parts are stolen or borrowed from other works, so why go through the charade?
My second suggestion is that the Copyright Office be outsourced to as many competing entities as can pay the price of entry, just like Internet domain registration, which is a more important registration service by far. As far as I’m concerned, Congress could kick the whole copyright registration process to Google Books, who could do it in their sleep and probably wouldn’t even see the need to charge a fee. In the end, the only value of copyright registration is having a legal, time stamped record of the creation of a work that will allow a lawsuit for copyright infringement to be filed on the best terms for the creator of the work. After that, it’s all up to the attorneys and courts, the Copyright Office serves no role as an advisor or a policing entity in infringement cases. As to the depository function of the Library of Congress, if they really want copies of all the books being published, they can ask publishers and authors to send them two copies, most will be more than happy.
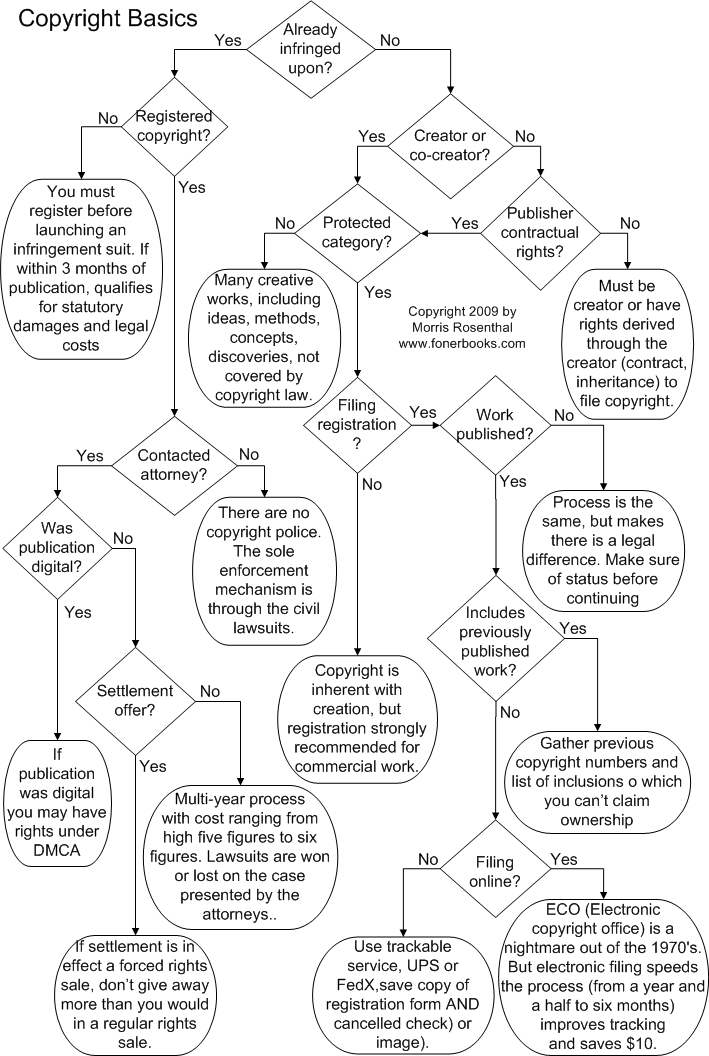
The one thing I would warn against is simply privatizing the Copyright Office to establish a monopoly agency, like Bowker, the monopoly ISBN registrar for the United States. Having to deal with and pay incredibly inflated fees to another Bowker would just about kill most aspiring small publishers. Of course, the continued existence Bowker may give somewhere for all the Copyright Office employees to go when they get fired - they would fit right in there.