A few weeks ago I completed my 2009 update for major book retailer sales as reported in their 2008 fiscal year. Each year (going back to 2001) that I do this sales analysis based on SEC filings it becomes more and more a story about Amazon, as the graph below illustrates:
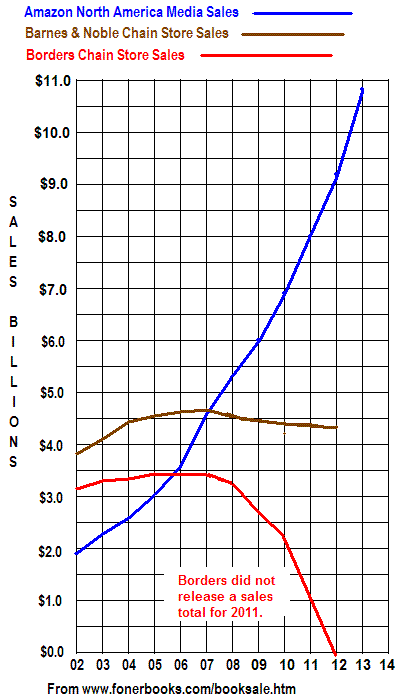
The other thing that happens each year is I receive questions, often from academics, asking me to break out how much of Amazon North American media sales are books, vs eBooks, DVD's, CD's, etc. Well, that's where the pigeons come in. I can't tell you an exact percentage, because they don't tell me. What I can tell you is that many years ago, when they were still selling less than Borders, Amazon let slip in a press release that non-book media sales made up a little less than a third of total. Since that time, CD sales have crashed as the music industry has been moved online and options to purchasing DVD's, ranging from Netflix and RedBox to digital downloads have multiplied. So my guess is that today, books and eBooks make up a good 75% of Amazon's media sales and I wouldn't be shocked if it was higher. I don't know the media mix at Barnes&Noble or Borders either since they don't report it.
Last month, I published a new Amazon analysis page, this one about how many Kindle ebooks are being downloaded. This turns out to be a fun exercise for graphing because you can come at it from two different directions. The first approach is to monitor Kindle sales ranks for a period of time, and then graph the actual number of downloads that took place. I'm referring to downloads rather than sales in this case because some Kindle downloads are free. The data points are exaggerated on the graph so you can see them.
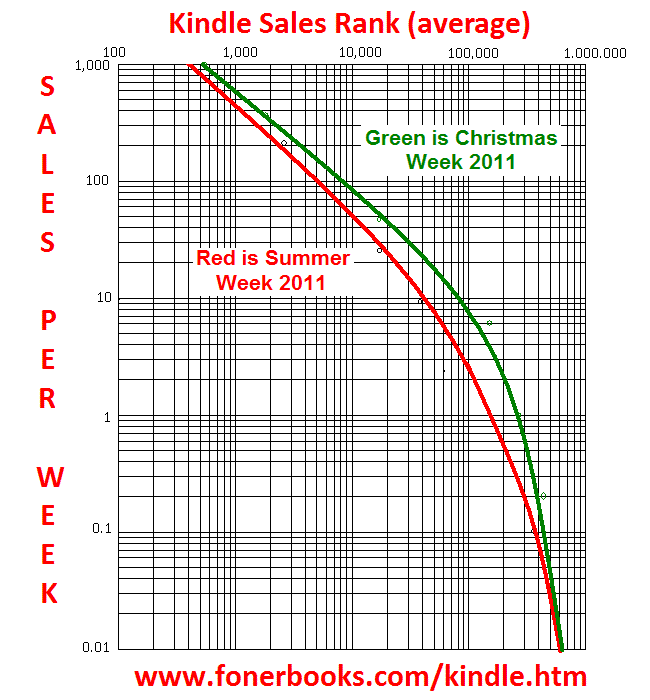
So why didn't I draw the line through the thickest area of points? Two reasons. First of all, Kindle ebooks with sales ranks in the high tens of thousands can go a week or longer without a download taking place. That makes the data extremely sensitive to which ebooks you happen to be watching and over what period of time you watch them. As time goes on, I'll move the line as required to express an average of the data points. Secondly, I drew the original graph by translation from my fairly stable Amazon sales ranks for books graph, after creating a reference line for the relative weight of book rankings vs eBook rankings. This was possible thanks to Amazon bestseller lists including both Kindle eBooks and printed books. You can work out the relative value of an eBook ranking by searching bestseller lists until you find that book (or one with a similar rank) closely bracketed by two paper books. You might find that paper book bestseller #13 on some list is ranked 10,516 and paper book bestseller #15 is ranked 10,563, so the Kindle eBook ranked #14 on the same bestseller list with a rank of 3,706 is selling at a rate between those two paper books. That's how I produced the larger Kindle sales rank equivalency graph.
Graphs aren't just for looking up single points of data. For example, when you have a curve expressing sales over time at different rankings, the area under the curve will give you the total sales occurring in that period of time. That's how I quickly estimated that Amazon is currently selling, or providing downloads of, 600,000 Kindle ebooks a week - by adding up stripes of area under the curve. What I've never done is use any mathematics software to find the function describing the curve of the moment and then used that function to make all sorts of definitive assertions about what is or will be. The curves are estimates, that's why engineers plot data points on graph paper. If all of the data points actually fall right on the line, something is suspicious, because the real world shouldn't line up that well with theory unless you are shooting cannon balls in a vacuum.
When I did my first graph of Amazon sales rankings back in 1998 or 1999, I used the area under the curve as a check to make up for the limited data points I had at the time. Since Amazon reported their total sales, and I could look at a large sample of books to estimate an average selling price, the total sales for the year (reported in their SEC filings) should come out around the same as the area under the curve multiplied by the average price. It seems to me I spent a good week working out that first curve, and back then, music was reported separately and use book sales didn't affect ranks.
The kind of Amazon numbers I don't try to deal with are those that are derived from non-Amazon sources, like the number of Kindle ebook readers sold. I've read a half dozen estimates of Kindle device numbers, but I'm not linking any of them because they didn't give me any confidence that their methodologies (rumor or "insider information") were valid. Another widely misreported Kindle number is that Kindle eBooks sell for $9.99 or less. While Amazon has made every effort to make the top bestsellers available for $9.99, many of the Kindle eBooks being downloaded are priced well above that, as a browse through any of the category bestseller lists of professional books, etc, will show. Kindle eBook prices in the $20 to $40 are common and Kindle eBooks priced above $60 can be found.
If you're wondering what makes a publisher so interested in math, aside from the obvious business ramifications, once upon a time I was an engineer working with radio frequency technology. Below is a twenty year old snapshot of a prototype antenna I built out of plumbing supplies for an insulated antenna used for air/sea interface communications. The math was horrendous (see Hankel functions) and the data was, to say the least, wavy.

5 comments:
The old photo shows that you had a lot of faith in C-clamps, or perhaps sea-clamps.
Michael,
C-clamps are proven technology, like graph paper:-) I wish I could have dug up a better picture, though, had some good ones of the dipole being driven underwater.
Morris
Morris,
Thanks for continuing to provide your vast knowledge. You site is an invaluable resource. Keep up the great work!
Per our previous conversation, if you want a free automated Amazon sales rank tracking solution with pretty charts and graphs, check out Metric Junkie. http://www.metricjunkie.com/
Mark,
Looks like it requires setting up an account to log in, makes the entry price of free to high for me:-)
Morris
Mark, wow, looks very cool, the entry price is definitely fine with me, I'm going to try it out. I've been looking for something like this.
Bryan
Post a Comment